团团虾声明:本文为完整翻译转载,原文 The Five Eras of KVCache,作者 Brian Zhang,发表于 2026 年 2 月 5 日。
引言
Key–Value Cache(KV cache / KVCache) 是现代 LLM 推理系统的基础构建块。它存储历史的 attention 状态,使模型能够高效地生成新 token,而无需过多的重复计算。
LLM 推理有两个阶段:Prefill 和 Decode。在 Prefill 阶段,为输入 prompt 中的每个 token 计算 attention 状态。在随后的 Decode 阶段,通过关注(attend on)与之前 token 相关联的 Key-Value,以自回归的方式逐个生成新 token。
 图源:
图源:vLLM、SGLang、TensorRT-LLM 和 MAX Serve 都构建在日益复杂的 KV Cache 管理之上。本文探讨 KV Cache 在这些推理引擎中的演进历程与作用。
时代 0:前 GenAI 时代(<2017)
在 Transformer 占据主导之前,深度学习由无状态的、前馈式架构主导,如 ResNet、YOLO、VGG 和 Inception。这些模型在推理步骤之间不需要持久化状态,因此即使在 ONNX 或 TensorRT 等推理框架中,KV Cache 的概念也根本不存在。
时代 1:连续 KV Cache(2017)
原始的 Transformer(2017) 奠定了最终主导整个机器学习领域的架构。这一设计与之前的模型截然不同,需要 KVCache 来高效地追踪与每个请求相关联的状态。尽管如此,Transformer 所带来的智能上的巨大飞跃,完全值得其增加的复杂度。
当时,早期的 LLM 推理引擎以朴素的方式实现 KV Cache:
- 对于每个请求,预分配一个连续的 KV 张量,容量为
max_seq_len个 token。 - 每个请求的存储量为
2 × num_layers × num_heads × head_dim × max_seq_len。

这种连续 KV Cache 的设计极其浪费内存,但相比于为每个 token 重新计算 attention 的 key/value,仍然带来了巨大的性能提升:
- ✔ 实现简单
- ✘ 由于
max_seq_len × batch_size因子的存在,内存用量急剧增长 - ✘ 由于有限的内存容量,
max_batch_size受到约束 - ✘ 由于变长请求的存在,内存碎片化严重
- ✘ 大多数请求远短于
max_seq_len,造成大量容量浪费
这就是 HuggingFace Transformers 等早期推理引擎的做法。
时代 2:PagedAttention(2023)
突破随着 PagedAttention 的提出而到来,由 vLLM 引入。其核心思想是借鉴操作系统中的分页技术,以固定大小的 page 分配 KV,并可以在序列增长时动态分配。

优势:
- ✔ 大幅提升内存利用率并减少碎片
- ✔ 支持数百乃至数千个并发请求
- ✔ 通过更大的 batch size 提升吞吐量
- ✔ 支持通过 Prefix Caching 实现 KV Cache 的高效复用——这对多轮对话工作负载是一个巨大的吞吐量倍增器
PagedAttention 成为 LLM 推理的事实标准,催生了 TensorRT-LLM 和 SGLang 等新的推理引擎。
时代 3:异构 KV Cache(2024)
如今,机器学习世界和 LLM 推理的格局已经远比过去复杂。新的优化手段以及现代多模态和混合模型需要多种不同类型的状态,每种都有各自独立的缓存需求。在这个时代,“KV Cache”这一术语的含义已经被远远超出了它最初的定义。
1. Speculative decoding(投机解码)
投机解码通过让一个小的 draft model 提前生成多个 token,然后用一个更大的 target model 在一次前向传播中验证并接受这些 token,从而加速 LLM 推理。使用这种技术时,需要为 draft model 和 target model 分别维护独立的 KV Cache。
2. Vision encoders(视觉编码器)
视觉语言模型(VLM)中的视觉编码器会生成大量的图像 embedding,可以跨请求缓存和复用。虽然这不同于传统意义上的 “KV Cache” 或 Prefix Caching 的概念,但它遵循相同的基本原则——对昂贵的中间状态做记忆化(memoization)。受益于此的模型包括 QwenVL 和 InternVL。
3. Quantized KV Cache(量化 KV Cache)
FP8 等低精度数据类型有助于减少 KV Cache 的存储需求,并依赖 per-tensor/row/block 的缩放因子来保持数值范围。这要求 KV Cache 的实现还要额外管理这些缩放因子的内存。
4. Sliding Window Attention(SWA,滑动窗口注意力)
滑动窗口注意力将每个 token 的注意力范围限制在最近的 window_size 个 token 内,而不是整个序列,从而减少内存和计算量。因此,KV Cache 管理和 Prefix Caching 必须跟踪哪些 token 落在当前窗口内,使得缓存命中和淘汰逻辑比全量注意力中更加复杂。
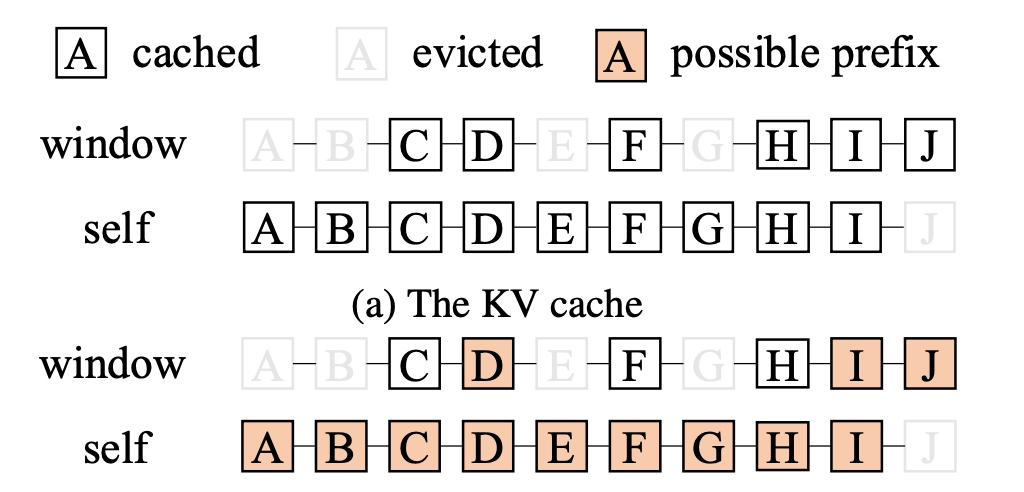 Fig 11. 图源:arxiv.org/pdf/2503.18292
Fig 11. 图源:arxiv.org/pdf/2503.18292
5. Mamba / State Space Models(状态空间模型)
Mamba / 状态空间模型用循环状态替代注意力,每个新 token 更新一个单一的大向量。这使得 Prefix Caching 变得更加复杂,因为推理系统必须决定何时以及如何对不断演化的状态向量做 checkpoint 或存储以备未来复用。
6. Composite Models(组合模型)
组合模型由多个子模型构成。例如,将 LLM 骨干网络与音频解码器组合是一种常见的模式。每个子模型可能需要维护独立的 KV Cache。
7. Hybrid Models(混合模型)
混合模型在单个模型内组合多种层类型,这通常需要维护多个 KV Cache 来处理每种层各自不同的注意力或状态机制。示例包括:
- 滑动窗口注意力 + 全量注意力(Gemma2/3, Ministral, GPT-OSS, Cohere)
- Mamba + 全量注意力(Jamba, Bamba, Minimax)
- 局部分块 + 全量注意力(Llama 4)
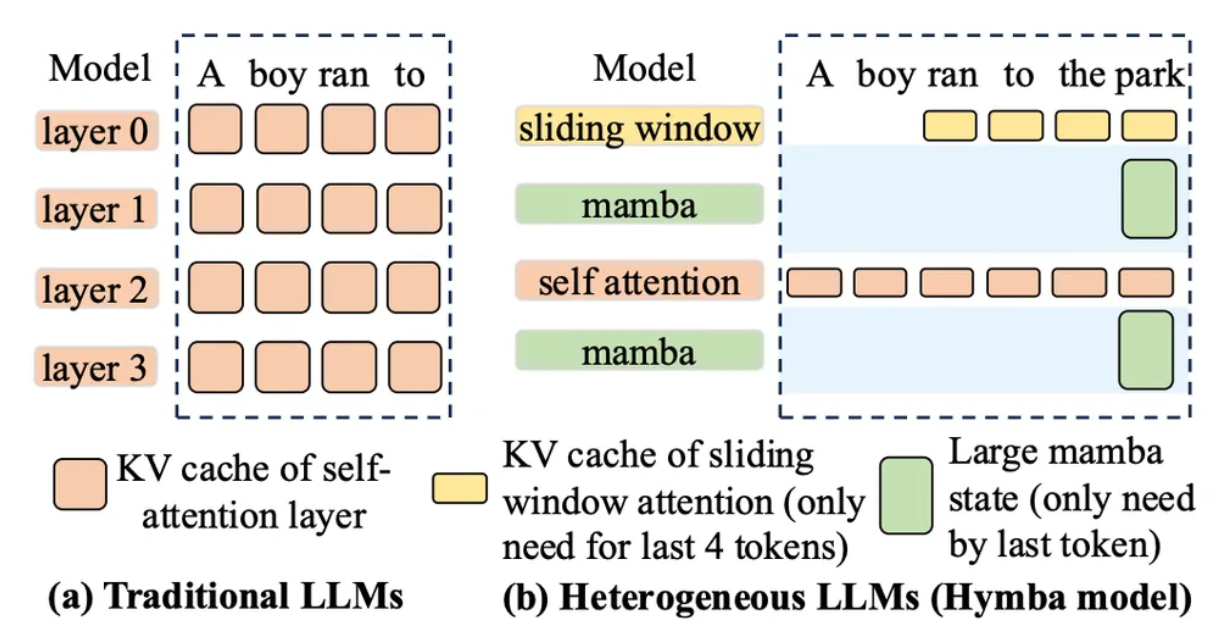 Fig 1. 图源:arxiv.org/pdf/2503.18292
Fig 1. 图源:arxiv.org/pdf/2503.18292
这个列表并不穷尽。还有大量其他思路,如用于联合文本-图像生成的 Transfusion、动态 KV Cache 压缩、Cross-Attention(不要与 Cross-Layer Attention 混淆)等。
这种异构性——不同形状、不同生命周期、不同属性的 KV Cache——催生了现代 LLM 推理引擎中专门的管理器。例如,vLLM 除了常规的 KV Cache 之外,还有视觉编码缓存、Mamba Cache 等。
这种设计正在显现出若干挑战:
- ✘ 多个 KV Cache 管理器导致的内存碎片,可能使 batch size 偏小
- ✘ 在服务启动时难以预测每种 KV Cache 应分配多少内存
- ✘ 各自独立的 Prefix Caching 实现导致缓存命中率不理想
- ✘ 多样性使得特性组合变得困难
时代 4:分布式 KV Cache(2025+)
随着 LLM 规模增长并处理日益增长的工作负载,单个 GPU 或节点已经不够用了。如今 LLM 推理和 KV Cache 正在走向多节点和分布式,常常横跨整个数据中心。管理海量规模的 KV Cache 需要新的技术,例如:
1. Disaggregated Inference(分离式推理)
LLM 推理被拆分为 Prefill 和 Decode 阶段,部署在独立的模型实例上进行独立的扩缩容,以减少干扰并优化资源利用率。一个核心挑战是如何高效地将 KV Cache 从 Prefill 节点传输到 Decode 节点。近期还出现了新的分离变体,如编码器分离(Encoder Disaggregation)。
2. KV Cache-aware Load Balancing(KV Cache 感知的负载均衡)
请求路由优先选择已经持有相关 KV Cache 的实例,最大化 prefix cache 命中率。这需要集群级别的视角,了解每个实例上 KV Cache 的当前状态。参考文档。
3. Hierarchical KVCache(分层 KV Cache)
为了增加 KV Cache 的容量,冷 page 可以从 GPU 显存溢出到更充裕的 CPU 内存或 SSD。这扩展了有效的 KV Cache 大小,同时将热的、频繁访问的 page 保留在 GPU 显存中以保证低延迟访问。从较低层缓存加载/存储某一模型层的 KV Cache 的较高延迟,可以通过与前一层 GPU 计算的重叠来隐藏。
许多新的 Kubernetes 原生推理方案如 Nvidia Dynamo、vLLM Production Stack、llm-d 和 AIBrix 已经涌现,试图驯服这种复杂性。然而,分布式 LLM 推理仍然非常困难:
- ✘ 许多现有的优化或架构仍然与分布式推理不兼容,如投机解码或 VLM
- ✘ 尽管有大量开源方案可用,但部署仍然需要专业知识和大量耐心
- ✘ 通过 InfiniBand 或 RoCE 的节点间 GPU 网络充满挑战,NIXL 等许多库仍处于早期阶段
- ✘ 大规模分布式系统存在许多固有问题,如管理故障切换、慢节点(straggler)、硬件缺陷、自动扩缩容等
时代 5:统一混合 KV Cache(2025+)
下一个阶段是构建统一的 KV 内存系统,其中许多异构 KV 类型共享一个公共内存池,而非各自为政的独立分配器。这个时代的另一个核心主题是追求所有可用优化之间的可组合性。
这一演进正在当下发生!
正在涌现的方案:
1. vLLM / Jenga——Huge Pages + LCM Sizing
使用 huge pages,页大小选取为较小页格式的最小公倍数(LCM),从而让不同的 KV 形状可以高效共存。统一的 Prefix Caching 设计,同时考虑多种 KV Cache 以改善均衡性和命中率。
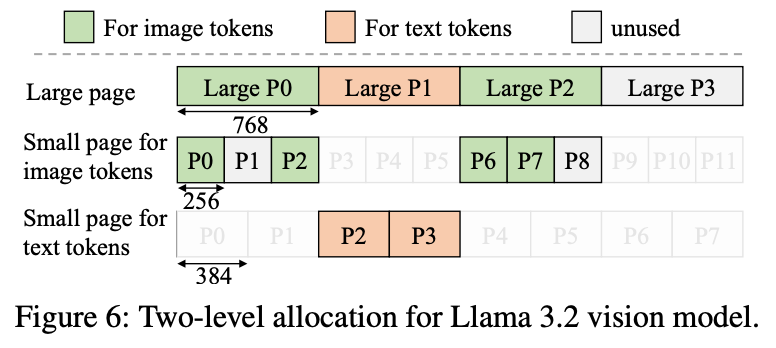 Jenga
Jenga
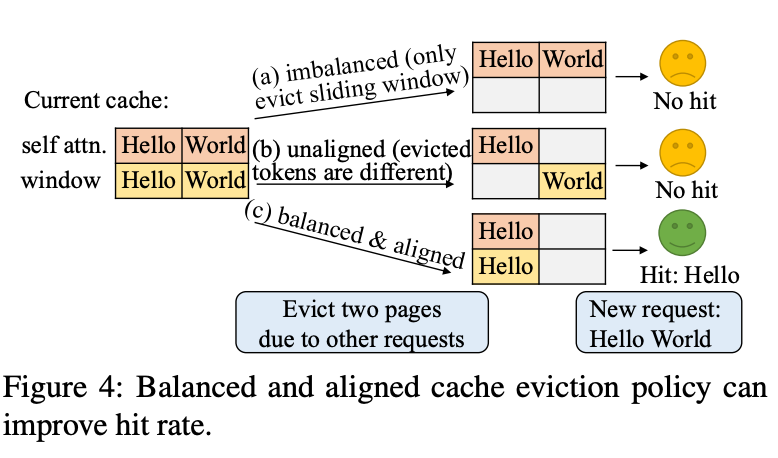 Jenga
Jenga
2. SGLang——CUDA Virtual Memory
SGLang 使用 CUDA Virtual Memory API 动态重映射显存,统一不同的 KV 区域。这使得 KV page 在虚拟地址上连续、在物理上分散。
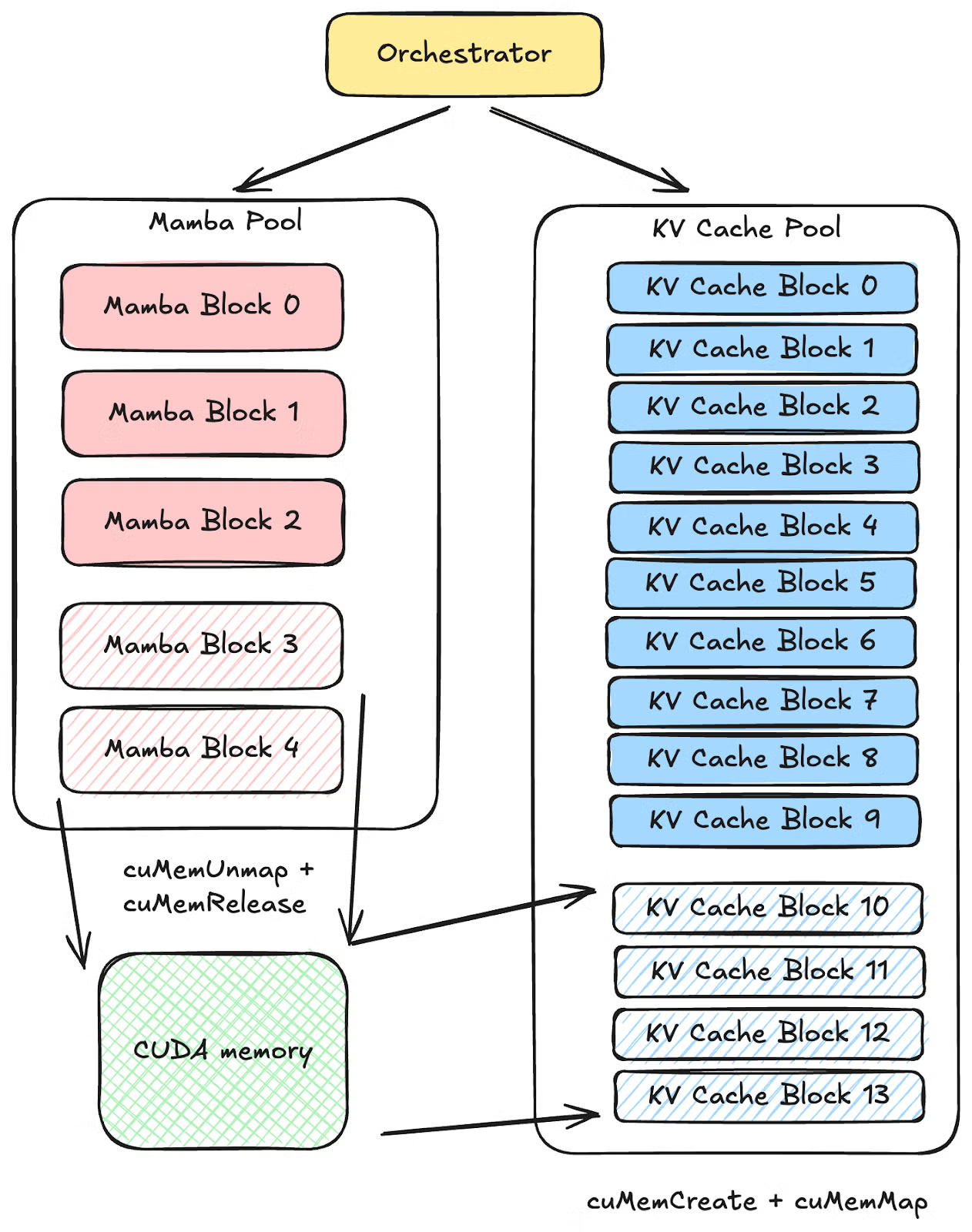 图源:PyTorch Blog
图源:PyTorch Blog
在特性可组合性方面也在进行大量投入。事实上,这是 2025Q4 SGLang 路线图的核心原则之一。例如,用户应该能够在分离式部署的多节点环境中,运行带有投机解码的 VLM 模型。这将需要长期的软件投入和对推理引擎核心组件的重新架构。
结语
最初只是一个小小的优化——缓存 attention 状态以避免重复计算——如今已演变为现代 AI 基础设施中最复杂的子系统之一。每个时代都带来了新的挑战:内存碎片、异构模型架构、分布式协调,以及现在——需要在所有这些维度上干净地组合的统一系统。随着新模型、新优化和新硬件的不断涌现,KV Cache 管理需要在 LLM 推理栈的每一层——从 GPU kernel 到集群调度——持续创新。
这正是我们从零开始构建 MAX 的 KV Cache 管理方式的原因。结合 Mojo 的性能和灵活性,我们正在构建能够处理当今模型、同时适应未来创新的基础设施。
想了解 MAX 如何处理你工作负载中的 KV Cache?从这里开始,或加入我们的社区与团队交流。
原文:The Five Eras of KVCache | 作者:Brian Zhang | 发表于 2026 年 2 月 5 日 | 来源:Modular Blog