团团虾声明:基于 brpc codebase,结合实际线上问题和日志,和 Gemini 深度讨论形成。
背景:漫长而致命的 5 分钟
生产环境里,大内存 C++ 服务(动辄几十 GB 的缓存引擎、检索服务)一旦段错误崩掉,操作系统写一个完整的 Core 文件可能要数分钟。这数分钟里,进程被内核挂起,一行业务代码都跑不了——但它还没死透。
上游调用方看到的景象是什么?这个节点连接没断,端口能连上,但请求打进去全都不响应。一个吞噬流量、永不回复的**“网络黑洞”**。
一、5 分钟假死期,TCP 在干什么
进程卡死了,但操作系统内核的 TCP 协议栈还在忠实地接管着该进程的所有 Socket。这就产生了两种极为迷惑的网络行为。
1. 已有连接:零窗口陷阱
客户端发来的数据包,服务端内核照常回 ACK。问题是应用层线程全卡死了,没人调 read()/recv(),内核接收缓冲区很快被打满。
缓冲区一满,服务端内核在后续 ACK 里通告 Zero Window。客户端收到零窗口通告后,停止发送数据,进入漫长的零窗口探测等待——表现为无尽的 Read Timeout。
从客户端视角看,连接明明还在,发出去的东西却永远等不到回音。
2. 新建连接:Accept 队列爆满后的静默丢弃
客户端发 SYN 建连,只要服务端 Accept 队列(全连接队列)还有空位,内核照常回 SYN-ACK,三次握手瞬间完成。客户端以为服务一切正常。
但应用层调不了 accept(),完成握手的连接很快把队列塞满(上限取决于 net.core.somaxconn 和代码里 listen() 的 backlog 参数)。
队列一爆,内核在默认配置下静默丢弃所有新 SYN 包。客户端的建连请求泥牛入海,最终触发 Connect Timeout。
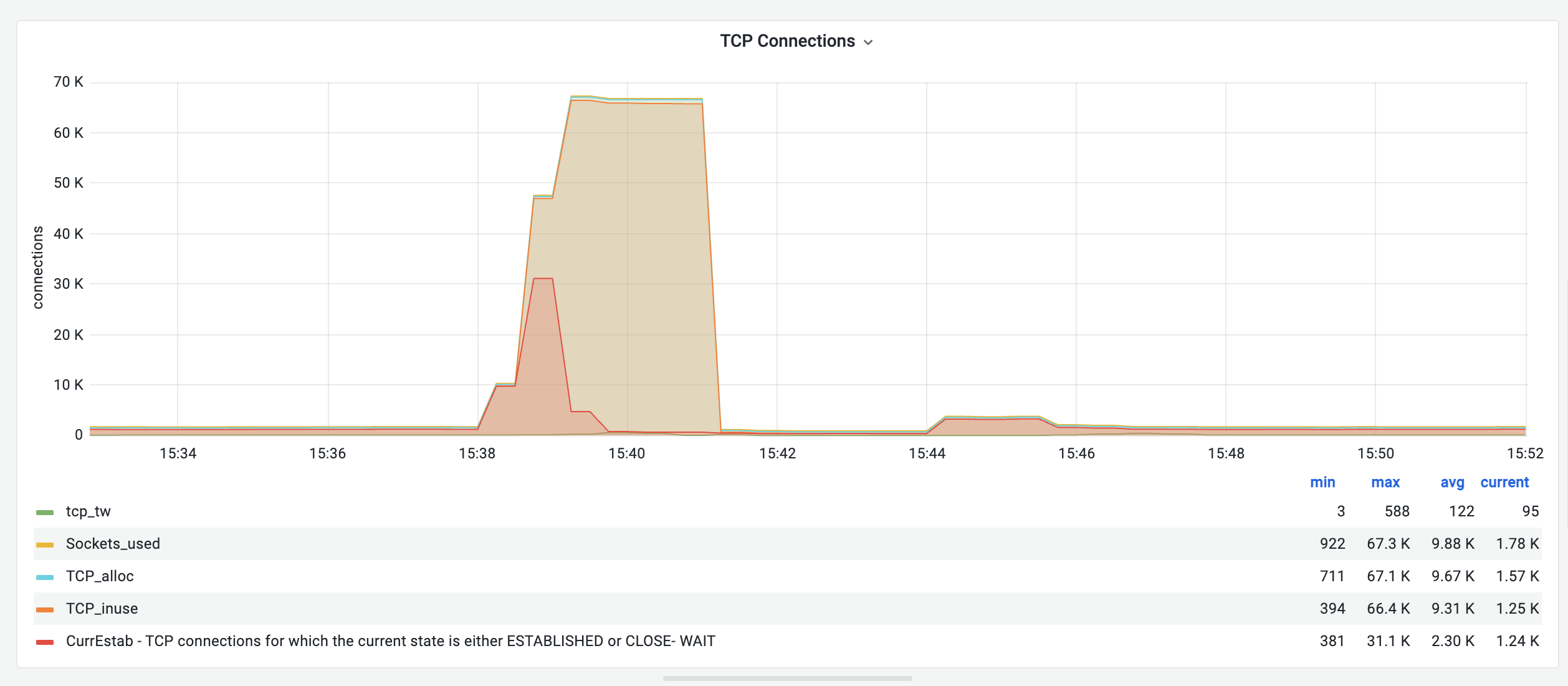
监控上往往能看到一次典型的”重试风暴”:ESTABLISHED 连接数飙到代码设定的 backlog 上限(如 32768),TCP_inuse 指标冲到 60K 以上,里面塞满了被上游超时丢弃的半开连接。
二、破局:brpc 客户端治理实践
面对”逻辑线程全卡死、IO 线程正常、TCP 能建连”这种极限场景,操作系统的默认行为帮不上忙。brpc 内部有处理”应用层假死”的机制,但默认配置扛不住,必须针对性调优。
1. 开启熔断(Circuit Breaker)——隔离黑洞
brpc 官方文档明确写了,Circuit Breaker 正是为”TCP 正常、请求全超时”这类场景设计的。
怎么配: 客户端显式开启 enable_circuit_breaker。
原理: 每次 RPC 结束,错误和耗时会反馈给 CircuitBreaker。错误率到阈值时,客户端自动将该节点 SetFailed 隔离,迅速切断打向假死节点的流量。
2. 升级 L7 健康检查(health_check_path)——防诈尸
brpc 默认健康检查有两个坑:一是只在节点被判死(SetFailed)之后才启动,二是默认只检查 TCP Connect。
在 Coredump 期间,服务端内核还在接受三次握手。默认的 TCP 健康检查会认为节点已恢复——然后流量打回去,又被黑洞吞掉,反复熔断。
正确做法: 配置 health_check_path,提供一个 /health 之类的 L7 接口。brpc 会等这个接口返回成功才真正让节点恢复可选状态,杜绝 Coredump 期间的”诈尸”。
3. 启用 Backup Request——拯救超时请求
对于”服务不返回但连接没断”的请求,brpc 默认的 Retry 机制没用(ERPCTIMEDOUT 不在默认重试错误码中)。
怎么配: 设置合理的 backup_request_ms。
原理: 请求发出超过该阈值还没收到响应,brpc 果断向另一个 Server 发副本请求,谁先返回用谁。这是最直接的请求级干预。
适用场景:读请求,或已实现幂等的写请求接口。
4. 配置 TCP_USER_TIMEOUT——打破零窗口僵局
针对已有连接因零窗口卡死的问题,可以用内核参数兜底。
怎么配: brpc 启动参数中配置 -socket_tcp_user_timeout_ms。
原理: brpc 底层会为 Socket 设置 Linux 的 TCP_USER_TIMEOUT 属性。当业务数据因零窗口长时间发不出去,或发出后长时间没收到 ACK,内核主动发 RST 断开连接,避免客户端线程被无限挂起。
注意:这个参数只管底层发送队列受阻的情况。如果小请求已经被系统 ACK 了、客户端只是在等业务响应,还是得靠 RPC Timeout 和 Backup Request。
三、服务端与基础架构的最终防线
客户端靠 brpc 的熔断和重试自保没问题,但服务端写 Core 期间根本无法执行任何”自我摘流”逻辑。基础架构层面还需要补刀:
- 告别庞大 Core 文件: 生产环境大型 C++ 服务建议接入 Crashpad 或 Minidump。段错误发生时,毫秒级收集关键堆栈和寄存器信息后迅速退出,把几分钟的黑洞期压到几毫秒。
- 内存豁免: 如果确实需要完整 Core 文件,分配海量业务缓存时务必调用
madvise(addr, length, MADV_DONTDUMP),让内核 Dump 时跳过这部分数据,大幅缩减落盘时间。
面对 C++ 服务的 Coredump 假死,服务端用 Minidump 缩短阵痛,客户端配 enable_circuit_breaker 加 L7 健康检查快速隔离,再辅以合理的超时和 backup_request_ms——这套组合拳是目前笔者所见的最优解。