团团虾声明:本文翻译自 vLLM 官方博客 Serving Agentic Workloads at Scale with vLLM x Mooncake,作者 Yifan Qiao, Trong Dao Le, Ao Shen, Zhewen Li, Bowen Wang。原文发表于 2026 年 5 月 6 日。
TL;DR: Agentic 工作负载会产生大量共享前缀,这些前缀在多轮交互中被反复重算。通过将 Mooncake 的分布式 KV cache 存储集成到 vLLM 中,我们在真实 Agentic 数据集上实现了 3.8 倍吞吐提升、46 倍 TTFT 降低、8.6 倍端到端延迟降低,并在 60 块 GB200 GPU 上几乎线性扩展。
Agentic 工作负载正在重塑 LLM 推理服务
随着 Claude Code 和 OpenClaw 这类 LLM Agent 的兴起,推理工作负载正在经历根本性转变。正如 Jensen 在 GTC 2026 keynote 中指出的,LLM 正在从简单的聊天机器人走向自主、长时间运行的系统——能够规划、推理并采取行动实现复杂目标。
Agentic 工作负载的独特之处在于它们的结构。它们通常由长视界、多轮循环组成,在推理步骤(模型处理上下文并产生中间思考)和动作步骤(模型发出工具调用并接收外部输出)之间交替。
为了量化这一行为,我们收集并分析了 Codex 和 GPT-5.4 在 SWE-bench Pro 数据集上的 trace。我们还开源了该数据集,鼓励社区进一步研究 Agentic 推理服务的工作负载特征。
图 1 展示了 Codex/SWE-bench Pro trace 的分析结果及一个代表性的 Agentic 会话。

这个模式非常惊人:到第 30 轮时,上下文长度增长到约 80K tokens,最长的上下文可以超过 180K tokens。但每次轮次通常只引入几百到几千个新 token。其余的部分都是模型已经见过的前缀。在整个数据集中,输入与输出的 token 比例约为 131:1。
如果我们能缓存这些前缀,缓存部分的 prefill 就几乎免费。真正的每轮成本只有新的增量部分。
在整个 Codex/SWE-bench Pro 数据集(包含 610 条 trace,每条中位数 33 轮)中,我们观察到:
- 94.2% 的缓存命中率
- 131:1 的输入输出比
- 每轮平均上下文增长约 2,242 tokens
- 每条 trace 的上下文从 12K 增长到 80K(中位数)
- 轮间延迟中位数 5.2 秒,P99 达 81.4 秒
然而,将 KV cache 本地卸载到 CPU DRAM 或磁盘,对 Agentic 工作负载存在两个主要限制:
- 有限的容量和驱逐。 一个 100K token 的上下文可能占用数 GB 的存储(例如 Kimi-2.5 FP8 KV cache 约 3.8 GB)。在一个服务多个长时间运行会话的繁忙实例上,这些大 prefix cache 会迅速占满本地容量并触发驱逐。
- 跨实例 miss。 为了负载均衡,路由器可能不会总是将同一会话的下一轮调度到同一个 vLLM 实例。如果会话被迁移到另一个实例,该实例从未见过该前缀,必须从头重算。
结论:我们不能再把推理服务看作一组孤立的 vLLM 副本。对于 Agentic 工作负载,各个实例需要共享一个分布式 KV cache 池,既提供更大的聚合容量,也提供跨实例的缓存命中。
用 Mooncake Store 构建分布式 KV cache 池
Mooncake 是一个开源的、高性能的 KV cache 传输和分布式存储库。vLLM 已经通过 MooncakeConnector 采用了 Mooncake 实现 prefill-decode(PD)分离,使用 Mooncake 的传输引擎在 GPU 之间传输 KV cache。现在,我们将这一集成向前推进一步,用 Mooncake Store 构建分布式 KV cache 池。
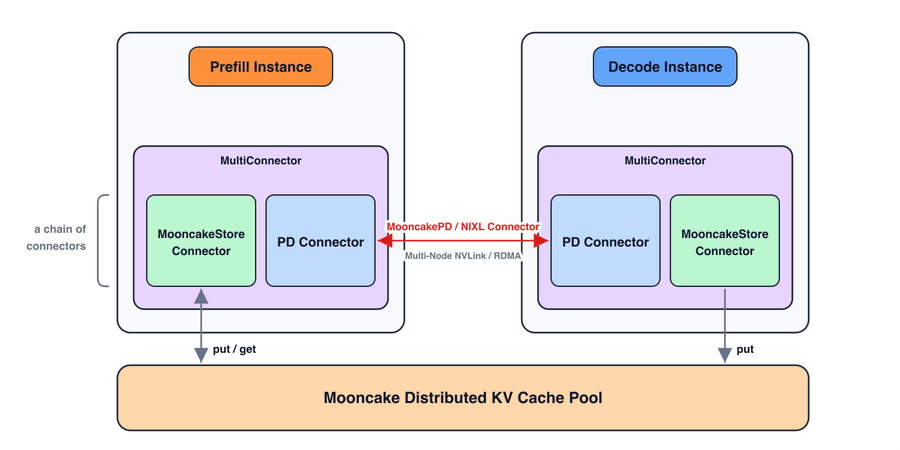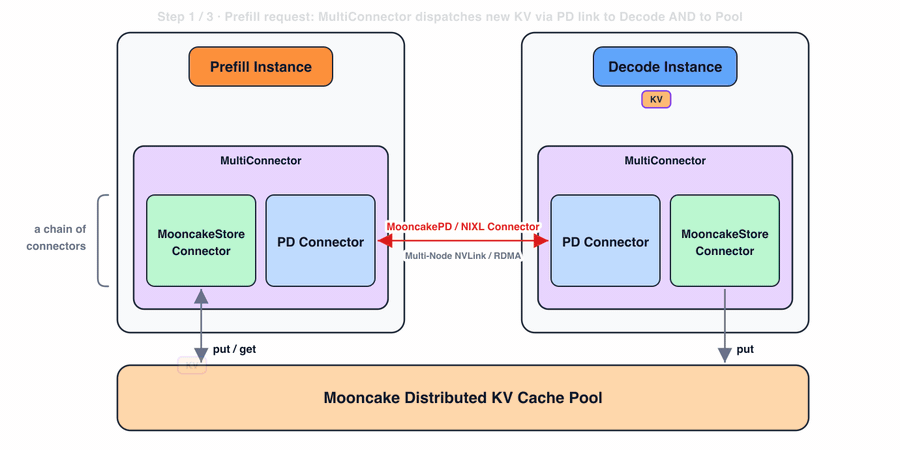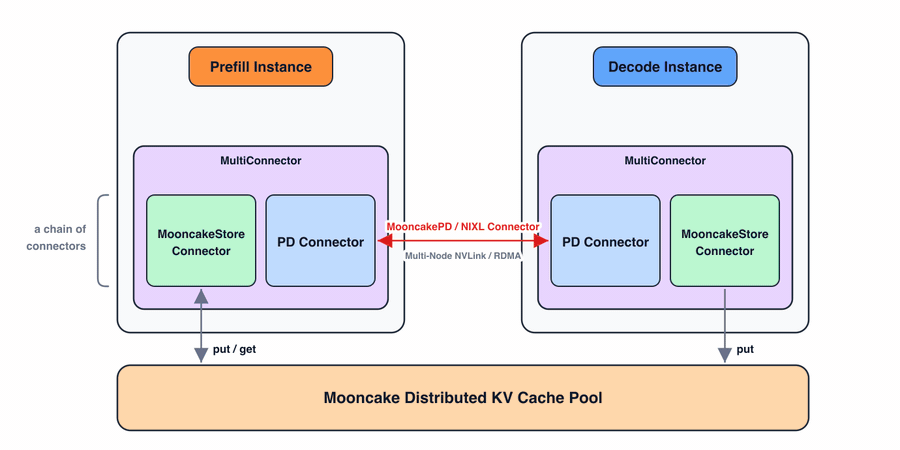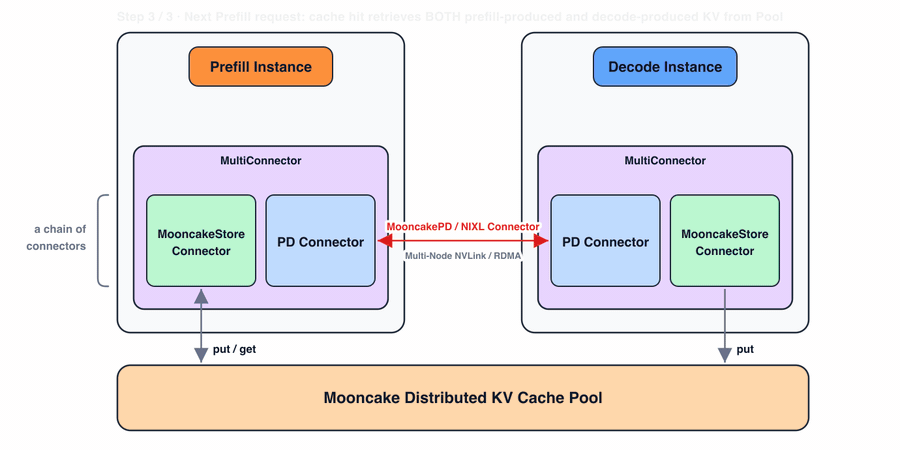
图 2 展示了整体设计。

在高层次上,Mooncake Store 提供一个 master 服务器和一组客户端。master 服务器在集群范围内运行,管理元数据,包括 KV block 的哈希、大小等。它还监控客户端健康和可用性,提供服务发现和死节点清理。
Mooncake 客户端运行在 GPU 节点上,管理本地的 CPU/DRAM/SSD 资源。客户端之间通过 RDMA 连接,用于 KV cache 传输。它们共同构成一个分布式 KV cache 池。
vLLM 的集成接入现有的 KVConnector 接口——这也是用于 PD 分离的同一个抽象。这个 connector 有两个角色:
- 调度器侧:当新请求到达时,vLLM 对 prompt 的 token block 进行哈希,向 Mooncake master 查询匹配的 KV cache block,并利用结果指导调度决策。
- worker 侧:vLLM 在每个 GPU worker 中嵌入一个 Mooncake 客户端,并启动后台线程进行数据搬运。GPU KV cache 内存被注册为 RDMA 缓冲区,使得可以通过 Mooncake 客户端直接进行 GPUDirect RDMA 读写,无需使用 SM 或经过 CPU 内存中转。
设计亮点
基于 GPUDirect RDMA 的无 SM、零拷贝 KV 传输
传统上,GPU 到 CPU 的数据传输要么通过 cudaMemcpyAsync(使用 GPU 拷贝引擎,但对大量小传输可能吞吐不佳),要么通过启动专用 GPU kernel 使用 SM 来拷贝数据。基于 kernel 的拷贝对大量小传输效果不错,但会与 GPU 上运行的其他 kernel 产生干扰。
我们采用第三种方法:使用 RDMA NIC 和 GPUDirect RDMA 直接在 GPU HBM 和 CPU 内存之间搬运 KV block。这一路径不需要中转缓冲区,也不消耗 SM。而且对于大量小 KV block 的传输也表现良好。
得益于 Mooncake Transfer Engine,传输路径还可以利用节点上的多个 RNIC,通过多 NIC 池化和拓扑感知的路径选择来聚合和更好利用可用网络带宽。
完全异步传输
虽然 RDMA 操作是异步的,但准备描述符和发起 RDMA 读写仍然需要不小的 CPU 开销。随着序列长度增长(更长的序列包含更多 KV block),这一开销也会增加。
为了防止阻塞主 CPU 路径(阻塞可能导致 GPU kernel 启动延迟),所有 RDMA 操作都在专用的后台 I/O 线程上运行。从 vLLM 的角度看,这使得传输路径完全异步。
通过 MultiConnector 同时启用 PD 分离和分布式 KV cache 池
这个集成也自然地通过 MultiConnector 接口扩展到 PD 分离。如图 3 所示,MultiConnector 是一个包装器,将多个子 connector 串联在一起。每个 connector 独立运行,不依赖其他 connector。
- Prefill:prefill 实例为 PD connector 准备 KV block,同时也通过 store connector 将其存入分布式 KV cache 池。对于缓存命中,vLLM 查询所有 connector,可以从 Mooncake Store connector 恢复匹配的前缀。
- Decode:当 decode 实例将 KV block 写入分布式池时,这些 block 立即对 prefill 实例可见。decode 本身目前不从池中读取:因为 vLLM 将每个请求调度到一对 prefill 和 decode 实例,prefill 实例从池中加载前缀 KV block,再通过 PD connector 转发给 decode。
我们正在开发从 prefill 实例和分布式池同时多路径加载 KV cache 的功能,以最大化可用网络带宽。
性能
当前实现可在此处获取。我们也提供了基准测试脚本。本文重点展示两个测试结果。
我们在 GB200 节点上运行 Kimi-2.5 NVFP4 模型,使用 PD 分离。prefill 实例使用 TP4,decode 实例使用 DP8 + EP。我们发现这一配置提供了最佳的延迟-吞吐权衡。
加速真实 Agentic trace
我们首先在真实场景中评估 vLLM,使用前文描述的 Codex Agentic trace。实验中我们部署了 1P1D 配置,共使用 12 块 GPU。
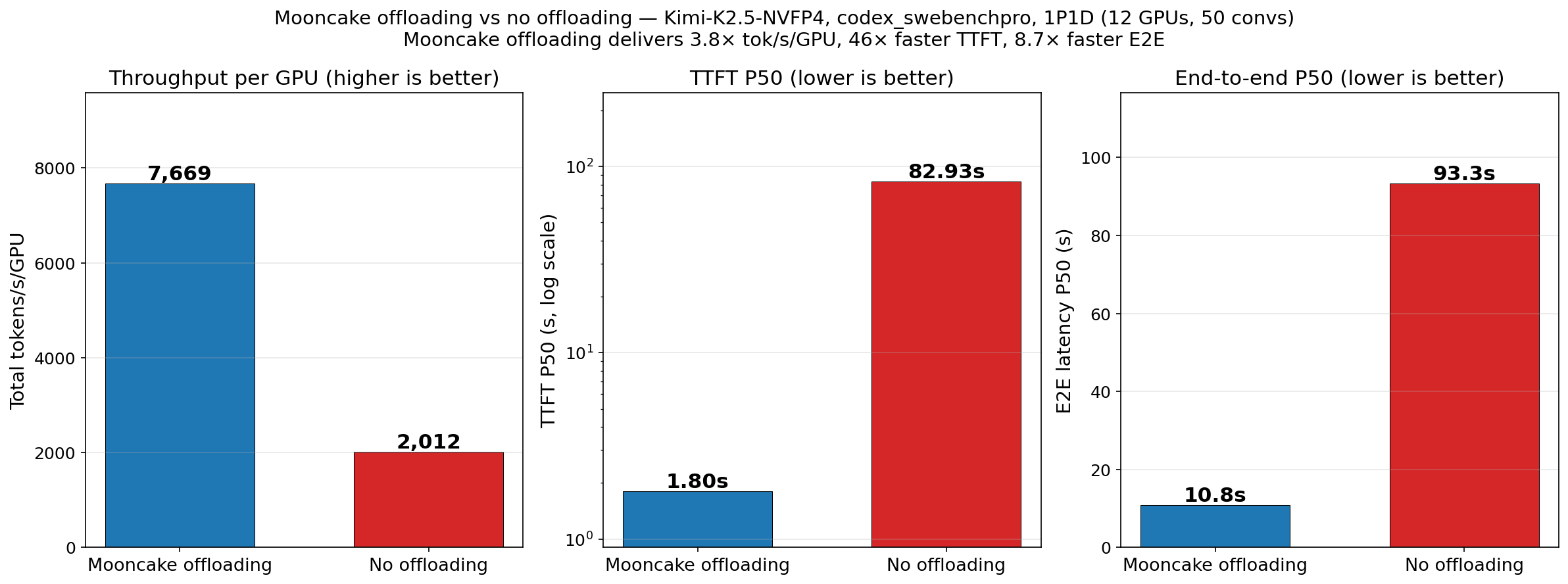
分布式 KV cache 池将 vLLM 的吞吐提升了 3.8 倍,P50 TTFT 和端到端延迟分别降低 46 倍 和 8.6 倍。这些增益源自缓存命中率的巨大提升:从仅缓存系统 prompt 的 1.7%,提升到几乎整个前缀都被缓存的 92.2%。
扩展到多节点
在扩展性测试中,我们进一步增加节点数量,并使用基于 Codex 工作负载构造的合成数据集进行受控扩展实验。
实验设置:
- 20K 公共 token(系统指令)
- 10K token 首轮输入
- 每轮输入长度 2,048 tokens
- 900 个输出 token
- 共 30 轮
- 会话数量随 GPU 数量扩展:75 → 150 → 225 → 300 → 375
- 参数选择大致与原始 Codex 工作负载对齐,保持总输出/输入比例约 1.3%
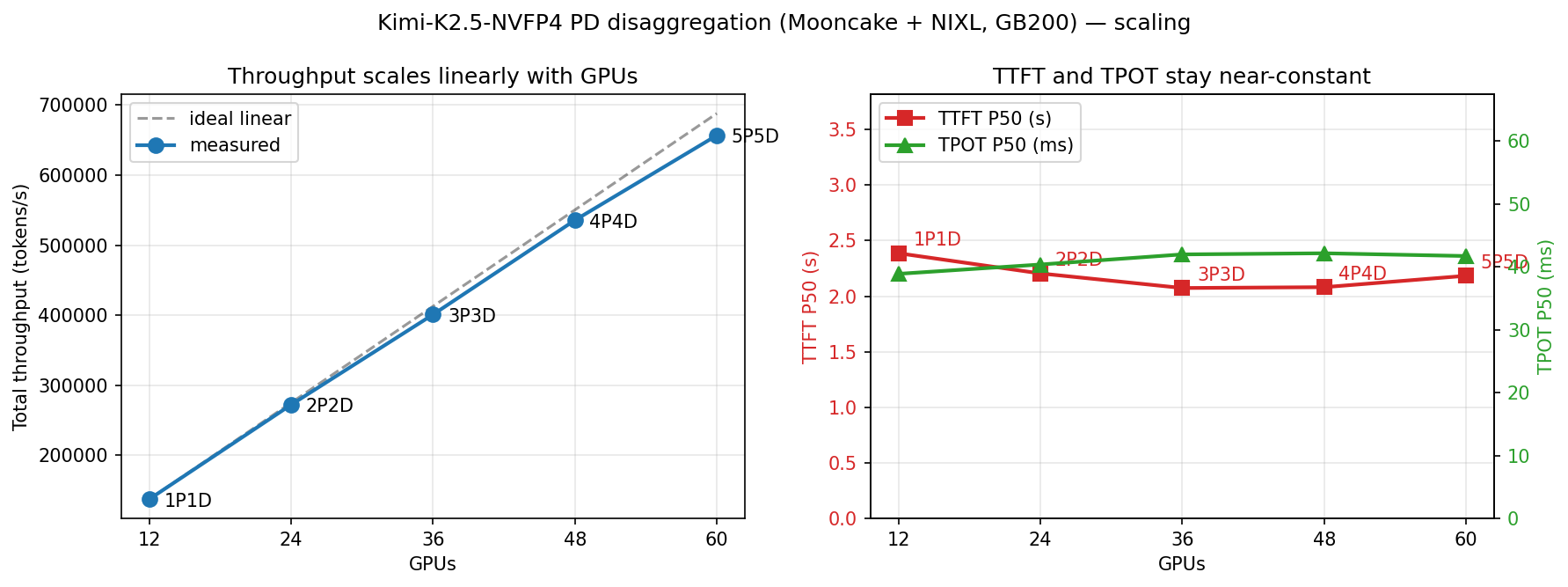
为了在跨节点流量下测试数据传输路径的压力,我们使用了轮询(round-robin)路由。因此,请求可能在不同轮次被调度到不同节点,经常需要从之前节点获取 KV cache。
如果没有分布式 KV cache 池,这种路由模式会导致大量缓存 miss 和严重的吞吐下降。有了 Mooncake Store,vLLM 始终将缓存命中率保持在 95% 以上,系统近乎线性扩展到 60 块 GPU。
这一结果表明,分布式 KV cache 池在保持高效数据传输路径的同时,大幅提高了缓存命中率,并且随集群增长具有良好的扩展性。
下一步计划
我们正在积极开发以下功能和优化:
- 分布式磁盘卸载。将存储层级扩展到 NVMe SSD 和分布式文件系统,实现更大的缓存容量。
- 混合模型的 KV cache 卸载。支持新兴的混合注意力机制架构,这些架构在不同层可能需要不同的缓存策略。
- 缓存感知路由。将请求路由器与 KV cache 池协同设计,使得轮次被定向到已经持有相关前缀的实例,先最大化本地缓存命中,再回退到分布式池。
- 进一步的数据路径优化。除了 RDMA,利用 NVIDIA multi-node NVLink 实现更快、多路径的 KV cache 传输。我们还在探索类似 DualPath 的方案,从 prefill 和 decode 实例同时加载 KV cache,以最大化聚合带宽。
致谢
vLLM Mooncake Store 集成的灵感很大程度来自于 vLLM-Ascend 的先前工作。我们特别感谢蚂蚁集团的 Chao Lei 提供的初始实现,以及 Inferact 的 Zijing Liu 提供的 Agentic trace 和分析。
我们也感谢 Approaching.AI 的 Jiahao Lu, Zuoyuan Zhang, Zihan Tang, Ke Yang;华为的 Pengbo Zhao, Fuqiao Duan, Tianyu Xu;阿里云计算的 Tianchen Ding, Xuchun Shang, Xingrui Yi, Teng Ma;蚂蚁集团的 Yunxiao Ning, Dejiang Zhu, Shoujian Zheng;以及 9#AISoft 的 Feng Ren 提供的宝贵技术反馈。
我们感谢更广泛的 vLLM 和 Mooncake 社区的支持和建议。最后,特别感谢 Inferact 团队在整个工作过程中的密切合作和讨论。
原文:Serving Agentic Workloads at Scale with vLLM x Mooncake — vLLM Blog, May 6, 2026